05.05.2021 г.
What is OCR? More importantly, what is OCR in the mobile world?
Simply speaking, OCR – optical character recognition – is a process of converting an image with text into textual information. It is a process of data digitization. Sometimes, new names, such as intelligent character recognition (ICR) or business card recognition (BCR) are used for some specific OCR tasks.

First OCR systems appeared almost simultaneously with the first digital computers. In the 1950s the usage of the commercial OCR systems began. These systems processed typewritten sales reports and converted them into perfocards. Since then, OCR has undergone a lot of changes. The main one being the replacement of the variety of classifiers with artificial neural networks (ANNs). And now it faces one of the greatest challenges – recognition of camera-captured images.
To understand the difficulty of this problem let us begin with an example. We captured the same document in three ways:
1) scanned it with 300dpi with Canon CanoScan LiDE 300 and binarized the result;
2) made a photo with iPhone 11;
3) shot a video with a web camera, split it and took a frame.
As you can see, the modern conditions of image acquisition demand the system to be robust to very different conditions.
| Binarized scan | 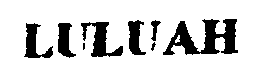 |
| Photo with iPhone 11 | 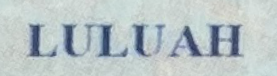 |
| Web camera video frame |  |
As we see, the image quality can differ drastically. The other thing to take into account is the standard OCR workflow, as shown in the picture.

So, most of the methods start with image preprocessing, especially with image binarization. It tends to simplify the segmentation process. Then, a segmentation algorithm is employed to divide the text line image into separate characters images. Finally, the system performs character classification. As a possible last step, sometimes postprocessing algorithms can improve the recognition accuracy.
In the case of mobile OCR software, two different problems arise: the constraints on computing power and uncontrolled image capturing conditions. With personal documents, sensitive banking papers, or COVID-19 test results you want to save as much privacy as possible, so the recognition on the cloud server is out of the question. The other way is embedded recognition that leads to the necessity of fast and resource-efficient algorithms. Secondly, with fewer restrictions for image capturing, more distortions appear. For example, projective distortions, blur, brightness changes, highlights, and so on. These distortions affect the preprocessing stage.
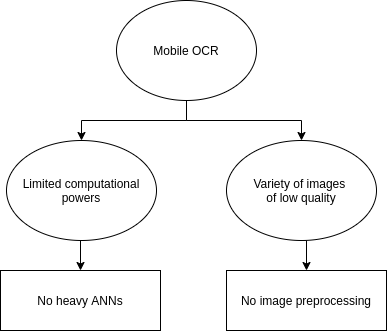
As a result, mobile OCR, on the one hand, forbids typical image preprocessing and acquires a lot of errors with standard image processing-based segmentation methods. On the other hand, due to computational restrictions, a lot of modern end-to-end ANN models, e.g., recurrent neural networks (RNN) and long short-term memory (LSTM), become inefficient or too demanding. Thus, to effectively recognize the camera-captured images on mobile devices (Android or iOS) we need to introduce brand new algorithms and rethink old approaches.
Rethinking the previously published approaches, image processing-based segmenters can be replaced with a segmentation network as it happened with classifiers some years ago. The most promising model for such a task is a fully convolutional network (FCN).

The replacement of a single camera-captured image with a video introduces a new concept of 4D OCR that presents new opportunities for recognition, first of all, the algorithms of interframe integration of recognition results. Moreover, it allows us to develop anytime recognition algorithms that use a variable number of frames to acquire results.
But what about real use cases for OCR software?
Let’s give some examples. All further mentioned processes can be improved with an OCR SDK.
Payments and transfers can be much faster with bank card recognition. Replacement of the manual data entering with a QR code, PDF417, or other barcodes scanning, as well as card recognition, tends to avoid annoying and unnecessary errors in the entered info and to improve user experience in banking apps, online shops, and even offline shops.
Ticket sales demand entering the personal data of thousands of people every day. Automatic MRZ scanning or passport recognition can speed up the selling process and minimize the number of errors in the data.
Remote client identification is a popular and essential modern feature for many tasks, including online shopping, online check-ins, and preliminary registration for medical services. Such a service allows to simplify the process for both the clients and the staff and to avoid the queues in the offices, shops, hotels, etc.
Banking services is the other industry to introduce ID recognition. In this case, any errors in entered personal data result in problems for a client, affecting their user experience and a further choice of bank. Integrated automatic ID cards, passports, or driving licenses recognition speed up the onboarding for new clients, simplifies the authentication, and decreases the number of human errors.
And what about publicly available OCR solutions?
Modern open-source communities and developers present a variety of freely available recognizers. Such solutions can be beneficial for learning purposes or, maybe, for some toy applications. However, they are dangerous for real-life commercial systems. Their main drawback is not the recognition accuracy (after all, you can try to fine-tune it). The main drawback is that they are vulnerable to attacks from the outside.
The attacks on neural networks is a widely studied scientific topic. The main types of attacks are data poisoning and evasion attacks with adversarial examples. In the case of data poisoning, the errors are injected into the ANN during the training stage. Then in the inference stage, the recognizer may produce some drastic specific errors. The only way to avoid it is to be sure of your training data. And how can you be sure in the data that you never saw? The evasion attacks try to make the recognizer produce an incorrect answer. Sometimes, the culprit can predefine this answer. For open OCR APIs, such examples can be calculated as they are, well, open, so you can just download the model and perform calculations.
Learn more about our Smart Engines OCR SDK and solutions
In Smart Engines, we develop OCR solutions that can work with photos, scans, or in the video stream. The capturing conditions are not a problem – a user does not have to focus on the image or even to provide good lighting conditions. Our software works autonomously on end-user devices, does not transfer client’s data anywhere, does not store it, and does not require internet access. The other essential feature is that we make use of data synthesis for training and do not employ any pretrained public models. It makes our solutions much more secure against external attacks.
We as a company provide three OCR-based products:
– Smart ID Engine – an SDK for scanning of more than 1600 types of ID documents from all over the world with Latin, Cyrillic, Arabic, and other writing systems;
– Smart Code Engine is a solution for bank cards, 1D and 2D barcodes, MRZ, and other codified objects recognition;
– Smart Document Engine presents automatic analysis and data extraction from various documents, forms, and questionnaires.
How our mobile OCR-technologies work
You can try our Smart Engines technologies with demo apps provided in App Store and Google Play.
If you want to learn more about the science behind our solutions, read the blog sections on our website, or search for us in Google Scholar.
Other blog posts
06.03.2023 03.03.2023Smart Code Engine: Revolution debit and credit card scanning technology
11.11.2022Stolen passport photos, fraudsters and facial fusion technology pose a threat to national security
All posts »